I’ve been a Chicago Bears fan for as long as I can remember watching sports. I have vivid memories of sitting on the floor of my grandparents’ living room, watching Bears vs Packers games where my late grandfather would torment me whenever Brett Favre would complete incredible passes downfield to his receivers against the Bears defense during their matchups in the mid-90s. There was something awe-inspiring about seeing the ball in frame one second, fly off Favre’s hand off screen with what appeared to be the velocity of a missile, come back into frame only a short few seconds later into the hands of a receiver running a route 150 feet away. Still, it was a travesty to have my grandfather, as Chicago as it gets, cheering for the Green Bay Packers. To be fair, I don’t think he was an actual Packer fan; he just appreciated the way Favre played the game stylistically - one of the original archetypes for gunslingers at the quarterback position in the modern era of football. My grandfather was the type of guy who watched shoot ‘em up westerns like Walker, Texas Ranger, so it would make sense why someone who played the game like Favre did had a certain appeal to him.
As I grew older, I had a brief stint of playing football in high school, but I never took it too seriously, and eventually gave it up as my interests began to wander elsewhere - a common phenomenon among budding teenagers. However, I’ve always watched football since then. I was hooked to the closest thing we have to a gladiator sport in the 21st century. The mix of gross physicality with athletic elegance and intricacies always caught my eye, as it’s a sport that stands out from the rest.
Fast forward to when I moved to Seattle in 2016, I gained access to a service that provided coaches’ film, commonly referred to as “All-22” (A22), because all 22 players on the field can be seen from a high vantage point in the stadium. This has several advantages from a coaching perspective, namely getting a bird’s-eye view of offensive/defensive patterns, alignments, personnel, and so on. All of these things (and more) can be useful when strategizing against opponents or when coaching your own players on fundamentals and technique. Now I’m no coach, but I can appreciate the intricacies of the game since I played at a novice level. Also, there is so much football content available from former/current players and coaches that provides insight into the techniques and game planning done during the week leading up to games, making it cool to be able to review the A22 yourself and verify what’s going on.
Now while the official source for viewing A22 (NFL+) provided by the NFL is great, it’s not perfect. It has pretty elite filtering, especially with the integration of the on field location data Next Gen Stats collects that tells you which players are on the field on a per play basis. This allows you to get very fine granularity when wanting to filter plays by player first. Despite this, you don’t really have the ability to natively take a set of plays for review (let’s say I wanted to watch all offensive plays in a game where the Bears had possession in their opponents territory). For one, I don’t think there are fine enough filters for this specific query, and secondly, you can’t select a list of plays to review as a set. Additionally, you cannot download the videos, which would make at least one of my last points moot as you could just download each individual video yourself as a set and review them in a playlist in your favorite media player.
A Rough Idea…
This got me thinking of a way to actually download the A22 at the very least for archiving purposes… but the more I marinated on the idea I thought I could create some sort of map between what happened on the play and the descriptions attached to each video. This would then allow me to roll a custom search engine that could let me create whatever type of queries I wanted that would only be limited to the data I could map the videos to.
The service I wanted to download videos from used MPlayer to stream videos with the download option disabled. So, suffice to say, I had to figure out how to download the videos.
Grooming the data
There are 3 videos per play that consist of 3 different camera angles (broadcast, sideline, and end zone):
<ul id="streamlist" class="collection native-scroll"
style="list-style:none;height: 550px; overflow-y:scroll;font-size:12px">
<li class="collection-item avatar playlist active" id="play-0" style="cursor:pointer"
onclick="loadStream("https://linktovideo.com";, 0,); ">
<p style="color:black;font-size:13px"><img
src="https://static.www.nfl.com/t_q-best/league/api/clubs/logos/CHI.svg" alt="" class="circle">CHI KO
CHI 35 - 8-C.Santos kicks 65 yards from CHI 35 to end zone, Touchback to the CAR 30. [Sideline]</p>
</li>
<li class="collection-item avatar playlist" id="play-1" style="cursor:pointer"
onclick="loadStream("https://linktovideo.com";, 1,); ">
<p style="color:black;font-size:13px"><img
src="https://static.www.nfl.com/t_q-best/league/api/clubs/logos/CHI.svg" alt="" class="circle">CHI KO
CHI 35 - 8-C.Santos kicks 65 yards from CHI 35 to end zone, Touchback to the CAR 30. [Endzone]</p>
</li>
<li class="collection-item avatar playlist" id="play-2" style="cursor:pointer"
onclick="loadStream("https://linktovideo.com", 2,); ">
<p style="color:black;font-size:13px"><img
src="https://static.www.nfl.com/t_q-best/league/api/clubs/logos/CHI.svg" alt="" class="circle">CHI KO
CHI 35 - 8-C.Santos kicks 65 yards from CHI 35 to end zone, Touchback to the CAR 30. [Broadcast]</p>
</li>
...First I took the HTML format and extracted the pertinent info (link, play id, and the video url) into a format for further processing. JSON seemed like as good a choice as any, so here’s what we got from our html_to_json_converter.py script:
[
{
"Sideline": {
"id": "play-0",
"url": "https://linktovideo.com"
},
"Endzone": {
"id": "play-1",
"url": "https://linktovideo.com"
},
"Broadcast": {
"id": "play-2",
"url": "https://linktovideo.com"
},
"description": "CHI KO\n CHI 35 - 8-C.Santos kicks 65 yards from CHI 35 to end zone, Touchback to the CAR 30."
},
...I created a script to download a single video first using a random url in the dataset above. Each video is a M3U8 playlist, and when downloading the video it’s segmented into 3 separate clips (per video), that then have to be stitched up into the original video. I used the ffmpeg python package to manage the processing. After some debugging and trying a couple different urls I was able to consistently download videos with no issues.
I ended up modifying this Python script (download.py) to iterates through each video url and download it. I also use a ThreadPoolExecutor for some concurrency since there are often over 400 10-20 second videos being downloaded per game.
Before attempting to batch download the videos with the modified script above, I created a new script (append_urls.py) that appends three new columns for broadcast_url, endzone_url, and sideline_url to a CSV. This script maps the corresponding URLs to a existing CSV of scraped play-by-play data via a pattern matching algorithm, matching the strings in the description key in my JSON file with the desc column in the CSV. I went through a couple iterations of this step trying different play-by-play data providers, but settled on the data offered via NFLVerse. It has a litany of great datapoints that would be highly helpful for being able to filter plays down using various queries. Also the descriptions were almost 1:1 to the descriptions I already had, so I could have a higher threshold on my confidence score for the pattern matching algorithm to successfully match a description value with a desc value on the CSV, giving me a higher confidence overall in my data integrity.
Lastly I modified the download.py script to map the dowloaded videos via their file names to the appropriate play. the script now appends 3 new columns broadcast_filename, endzone_filename, and sideline_filename. I used a schema for the filenames so you can see general info on the play:
PLAY_POSSESIONTEAM_DOWNDISTANCE_FIELDLOCATION_CAMERAVIEW_UNIQUEHASH

So now we have completely mapped play-by-play data and we only had to append 6 additional columns of the source URLs of the video files and the locally downloaded files on my computer. Now the fun comes the part.
Filtering down the plays
As I mentioned earlier the filters are based on the data available in the CSV of play-by-play data, which is fortunately pretty extensive. I would love to get access to some of those juicy datapoints from some place like NFL’s Next Gen Stats, but obviously they have privileged access and proprietary data sources, so we work with what we have.
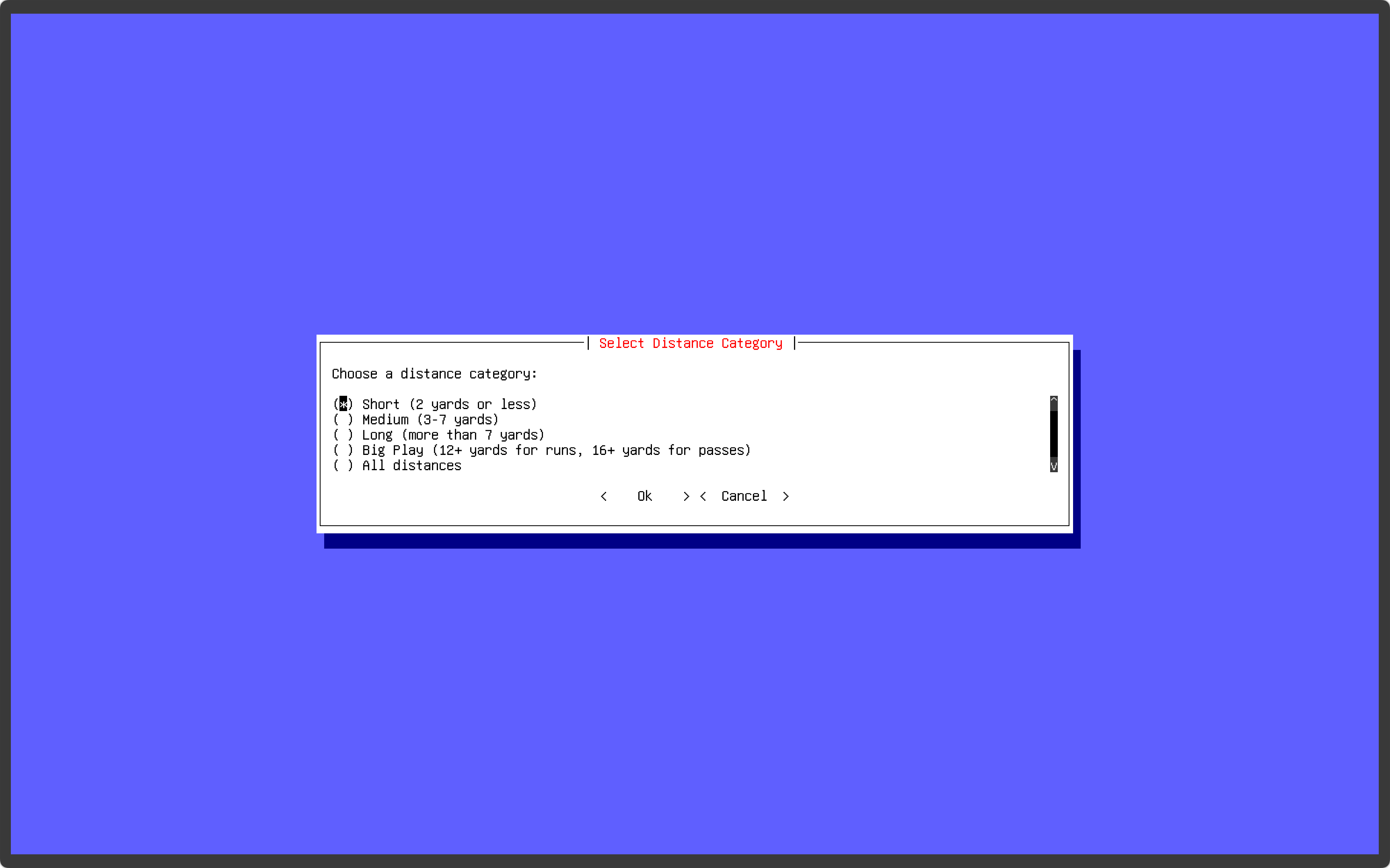
I started off using a script with a few one-off queries, just to see test working with the CSV data. After making sure that the outputs were exactly what I was requesting then I decided on making a barebones terminal interface using Prompt Toolkit that way I could effectively add as many filters as I want, then tick them off as I pleased to filter down a set of plays.
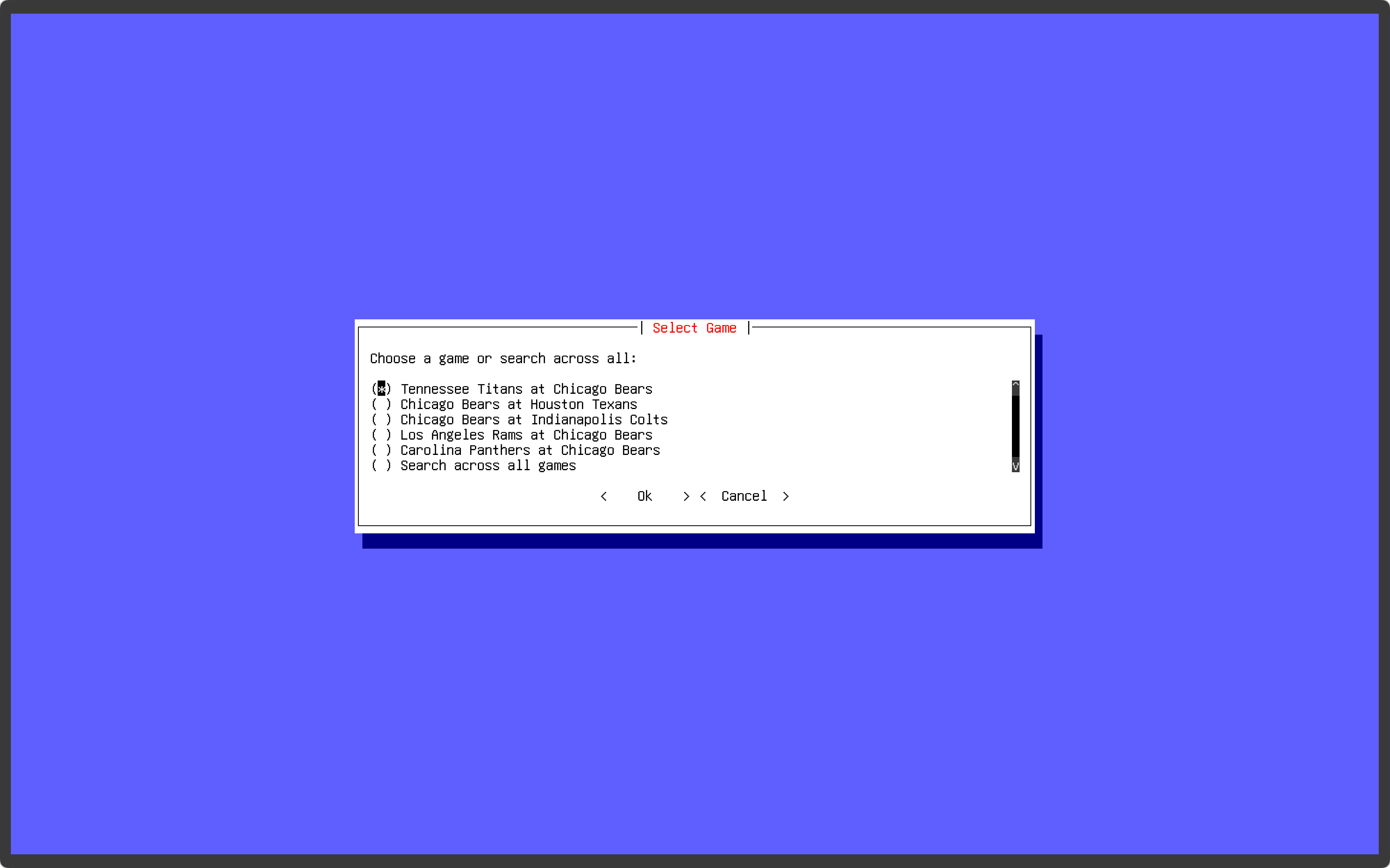
I got very familiar with the CSV column headers to make sure my implementations of the filters made logical sense. This was a little tedious as there are nearly 400(!) column headers in this scraped play-by-play data! Some of it is duplicate data as well (from different sources I’m guessing), so sure, I could have evaluated what data was necessary to keep and then delete the rest, but since the data set is so extensive, and I’m a bit of a data hoarder, I decided it would be best to keep it in case I find a use for it later. Plus it’s quite awesome having the video associated with some of the advanced data mapped directly to it such as the probabilistic data (EPA), as I think I could create some unique visualizations with it in concert with the videos I have mapped to it.
Here’s an example video that I made of all of Chicago’s sacks and QB hits in week 5 vs the Carolina Panthers from the end zone view:
Glorious.
To be clear, the screenshot of the prompt interface above is my sort_videos.py script and it outputs all of the individual videos I query into a new directory like so (ignore the first 3 files):
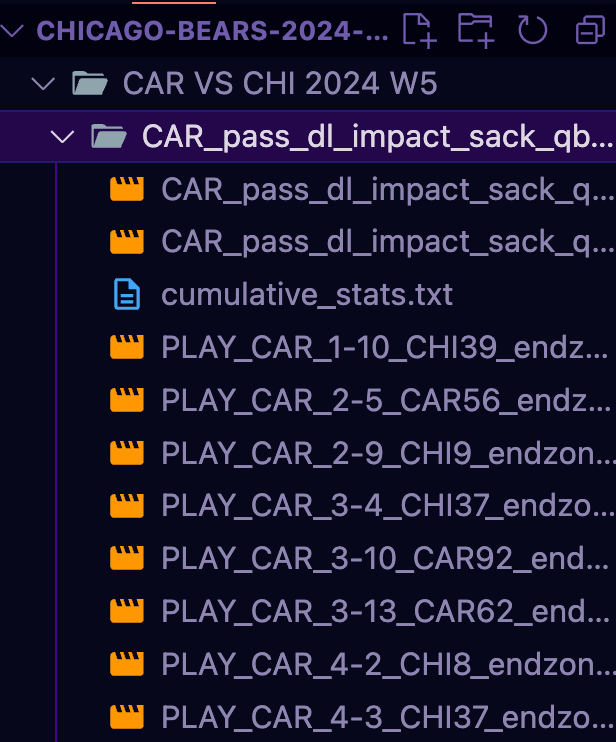
I then take a separate script (stitch.py) to stitch all of the videos into a single video (taking into account the actual order the plays occurred). I also have a flag on the stitching script to add the overlay that can be seen at the top of the video for context of what occurred on the play. All made possible thanks to the data in the CSV!
I’m extremely happy with where this project is now, especially from where I started. However, the more I’ve been using it, I figured there’s definitely more I can do to make it even nicer to use, and some interesting technologies that could also be integrated into it.
A few things I plan to explore building out over the next few weeks are:
- A proper GUI (Electron App)
- The GUI would allow for easily toggle-able filters and annotations on the video extending it into a review tool.
- Ollama integration for queries in plain english (ex. “Show me all plays of the Chicago Bears offense on 3rd down vs the Carolina Panthers defense”)
- Sure, I could go with OpenAI/Anthropic/etc., but it would be neat to just have everything you need locally. Plus these edge models are getting pretty good for tasks like these. You can even take the base model and modify weights and/or train them for specific tasks such as this.
- OpenCV integration
- Player tracking
- Ball path tracking
I’m still debating on if I want to open source this tool as I build it, but that decision will come at a later date. Obviously there are many considerations with that decision, and if I did it would certainly be a BYOV (Bring Your Own Video) deal. For now I’m just enjoying building the project, exploring some new technologies, and putting it all together.