I’ve been spending a decent amount of time practicing my Spanish lately, and one of the best ways I’ve found is through immersing myself in Spanish content. The primary strategy I’m using to learn Spanish is via comprehensible input.
This isn’t some super revolutionary idea, in fact Dr. Stephen Krashen broached the topic some 40 years ago. However, tools such as Language Reactor and Lingopie have been recently gaining in popularity to leverage that monthly Netflix subscription in the name of picking up some new linguistic skills, while simultaneously watching your favorite shows. Here are a couple of other YouTube videos that talk about using comprehensible input while watching movies/TV series:
Now there’s certainly no dearth of Spanish content to consume, and you could even use YouTube as a free alternative to Netflix if you’d like another option for video based content, but there’s another form of content that is often forgotten about or maybe even outright dismissed…
Radio
Specifically talk radio. It’s on for the majority of the day, with dozens of different stations, and the topics can range from business, to local/national/international news, sports or even tabloid-y gossip and celebrity talk. There’s something for everybody. You could also say the same about podcasts - and there is certainly no shortage of podcasts out these days, but you’re beholden to the cadence of whatever the podcast release schedule is, which could be maybe once or twice a week, and the topic(s) of conversation could become a bit stale if that matters to you. The cool thing about radio is you can just turn it on at any time of day and there’s something on. You’ll get exposure to various different topics, speaking styles and cadences, which will help with your listening comprehension.
Approach
So, how will Whisper help us learn a new language? Well first, let’s outline what we’re doing:
- We’ll record some audio from a live radio broadcast
- We’ll take this audio and run it through Whisper to get a full audio transcript
- We can now take this transcript and recorded audio to use for practice materials
Prerequisites:
- You’ll need a way to record the radio broadcast. We’ll be creating a python script to automate it.
- You’ll need a internet link to a radio station broadcast. For Spanish I use Radio Formula, who has dozens of different stations around Mexico. Click whatever station you want and copy the link to the resulting page.
- You’ll need to install Whisper.
- You’ll need a python environment to run the python script.
Info
Alternatively, if you prefer, you could use Quicktime (on Mac) to record the audio broadcast. You’ll have to set up something like BlackHole in order to record the system audio through the record function in Quicktime. This is the only thing that has to be done locally.
Also, if you’d rather not spend the time to set up or run Whisper locally or your computer isn’t powerful enough to run it, here’s a link to the whisper-large-v3 model (the most powerful model) space on huggingface.co: https://huggingface.co/spaces/hf-audio/whisper-large-v3
So, without further ado, let’s get started
Recording Audio
INSTALLATION
- Install Python 3.x on your system.
- Install required Python packages:
pip install pytz tzlocal - Install FFmpeg on your system.
- Download the script (below) to your local machine.
USAGE
- Run the script with desired options:
python script_name.py --url [STREAM_URL] --start [START_TIME] --end [END_TIME] --output [OUTPUT_FILE] --timezone [TIMEZONE] - All arguments are optional except —url. However, there is a default provided, which you can replace for your individual use case.
- Times should be in “YYYY-MM-DD HH:MM:SS” format.
EXAMPLES
- Record a 5-minute clip:
python script_name.py --url https://example.com/stream - Schedule a future recording:
python script_name.py --url https://example.com/stream --start "2023-05-01 14:00:00" --end "2023-05-01 15:00:00" - Specify output and timezone:
python script_name.py --url https://example.com/stream --output my_recording.wav --timezone "America/New_York"
Tip
When running the script to record while you’re away, you may want to prepend it with
caffeinate -sto keep your system from sleeping while the script is running. You can of course still lock your screen and the script should still record without issue.
Here’s the full python script:
import time
import argparse
from datetime import datetime
import pytz
from tzlocal import get_localzone
import subprocess
import sys
def prompt_user_for_immediate_start():
while True:
response = input("Start time is in the past. Would you like to start recording immediately? (yes/no): ").lower().strip()
if response in ['yes', 'y']:
return True
elif response in ['no', 'n']:
return False
else:
print("Please answer with 'yes' or 'no'.")
def wait_until(target_time):
now = datetime.now(pytz.utc)
if target_time <= now:
if prompt_user_for_immediate_start():
print("Starting recording immediately.")
return
else:
print("Exiting script.")
sys.exit(0)
while datetime.now(pytz.utc) < target_time:
time.sleep(1)
def record_stream(url, start_time, end_time, output_file, timezone):
if start_time:
wait_until(start_time)
start_record_time = datetime.now(timezone)
print(f"Recording started at {start_record_time}")
# Calculate duration
if end_time:
if end_time <= start_record_time:
print("End time is in the past or equal to start time. Using default duration of 5 minutes.")
duration = 300
else:
duration = (end_time - start_record_time).total_seconds()
else:
duration = 300 # Default 5 minutes
# FFmpeg command
ffmpeg_cmd = [
'ffmpeg',
'-i', url,
'-t', str(duration),
'-acodec', 'pcm_s16le', # 16-bit PCM
'-ar', '16000', # 16 kHz sample rate
'-ac', '2', # Stereo
output_file
]
# Run FFmpeg
process = subprocess.Popen(ffmpeg_cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = process.communicate()
if process.returncode == 0:
end_record_time = datetime.now(timezone)
print(f"Recording completed at {end_record_time}")
print(f"Saved as {output_file}")
else:
print("Error occurred during recording:")
print(stderr.decode())
def main():
local_tz = get_localzone()
# Arguments
parser = argparse.ArgumentParser(description="Record a radio stream.")
parser.add_argument("--url", default="https://n0e.radiojar.com/u9zvqwen3p8uv?rj-ttl=5&rj-tok=AAABkFBnbVkAN0N1pZr20iAXpg", help="URL of the radio stream")
parser.add_argument("--start", help="Start time in format YYYY-MM-DD HH:MM:SS")
parser.add_argument("--end", help="End time in format YYYY-MM-DD HH:MM:SS")
parser.add_argument("--output", default="recorded_stream.wav", help="Output file name")
parser.add_argument("--timezone", default=str(local_tz), help="Time zone for start and end times (default: local system time zone)")
args = parser.parse_args()
tz = pytz.timezone(args.timezone)
now = datetime.now(tz)
if args.start:
start_time = tz.localize(datetime.strptime(args.start, "%Y-%m-%d %H:%M:%S")).astimezone(pytz.utc)
if start_time < now:
print(f"Start time {start_time} is in the past.")
if prompt_user_for_immediate_start():
start_time = None
else:
print("Exiting script.")
sys.exit(0)
else:
start_time = None
if args.end:
end_time = tz.localize(datetime.strptime(args.end, "%Y-%m-%d %H:%M:%S")).astimezone(pytz.utc)
if end_time < now:
print(f"End time {end_time} is in the past. Using default duration of 5 minutes.")
end_time = None
else:
end_time = None
print(f"Using time zone: {tz}")
if start_time:
print(f"Start time: {start_time.astimezone(tz)}")
if end_time:
print(f"End time: {end_time.astimezone(tz)}")
record_stream(args.url, start_time, end_time, args.output, tz)
if __name__ == "__main__":
main()I added a few arguments that I thought might be useful.
--startand--endthis is nice for DVR-esque functionality if you found a specific radio block or show that you want to record at a specific time of day.--timezoneI’m in North America, but maybe I want to record a French or Japanese radio show. In either case it might be useful to specify a timezone if I know what time a particular show comes on in the local timezone that it’s being broadcast.
Tip
If you’re looking for a place to source other online radio streams, I’ve found Streama to be a good source of streams all over the world. It also labels each channel with genre tags, so talk radio should be easy to find for example. When you find a show you like, open it on the website, then inspect element on the radio player. You can find the url for the stream to then use in the above script.
Transcribing audio
Now that we have recorded an audio clip we can transcribe the audio. I’ll go over two methods you can use Whisper to do this.
Option 1: locally via installed Whisper (recommended)
This is what I would personally recommend as it’s a lot more flexible, and automates the process entirely. I’ll remind you to make sure you’ve installed Whisper as mentioned above. After you’ve installed it you can run the following command within your whisper directory:
./main -m /whateverpath/whisper.cpp/models/ggml-large-v3.bin -f whateveraudio.wav -l [LANGUAGE] -otxtBreaking this down a bit, we start with the ./main for the executable, then we define the model we’re using with -m /whateverpath/whisper.cpp/models/ggml-large-v3.bin. -f whateveraudio.wav is the path to your audio file to be transcribed. -l [LANGUAGE] is to define the spoken language (this isn’t necessary, but it gives me more consistent results). Lastly -otxt outputs a text file of the transcription, which is what we need for our practice.
The output should have some decent formatting with new lines for different speakers and punctuation for complete sentences and separate thoughts.
Option 2: online via Hugging Face space (not recommended)
This is the easiest, and least resource intensive method. Simply navigate to the hugging face link provided above in the info callout. Here’s what you should see:
Make sure to click on the Audio file tab. Now simply upload your audio, make sure the transcribe task is selected, then submit. You’ll get a large block of the transcribed text as so:
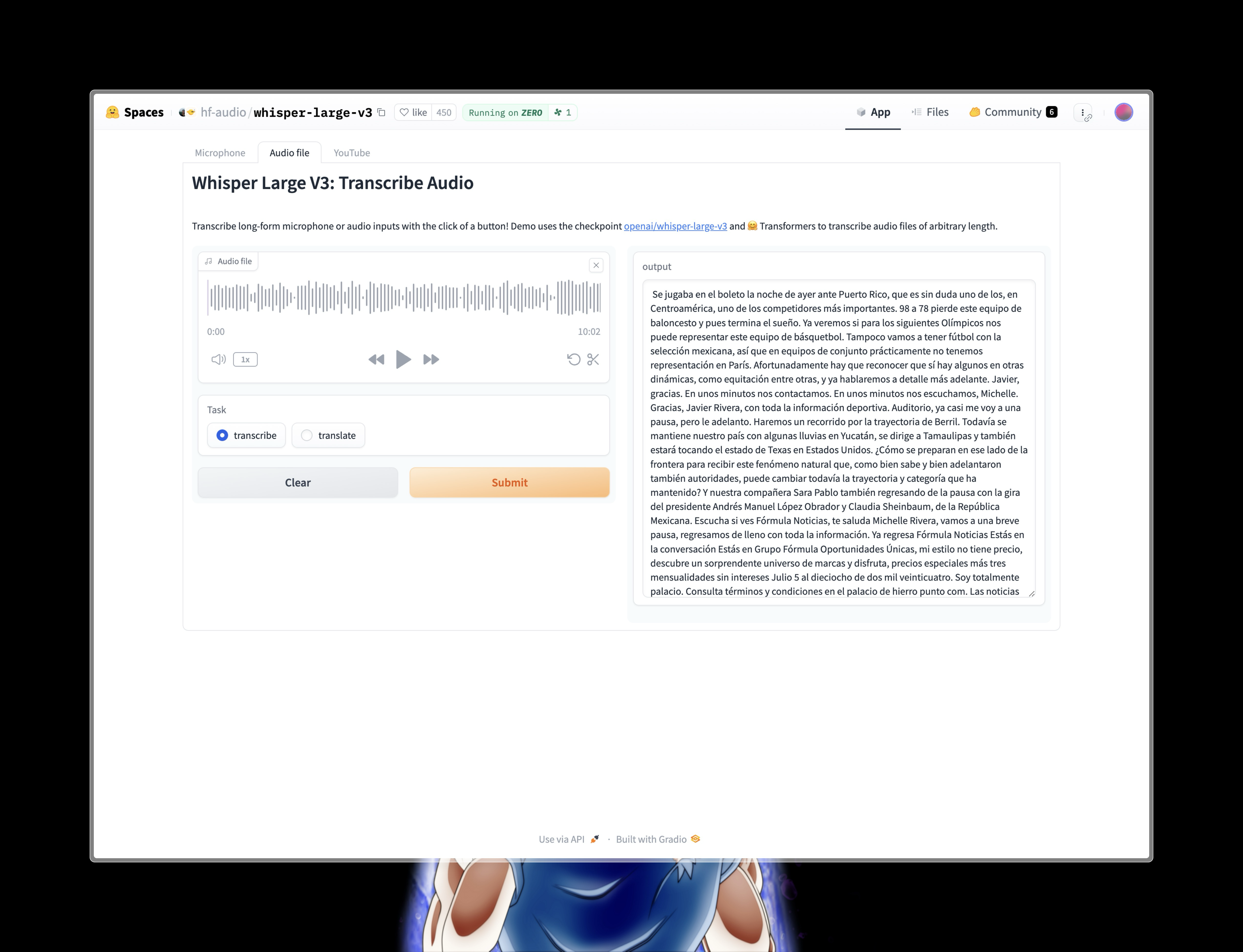
One thing to know about transcribing this way is you’ll have to keep the audio clips relatively short. In the example above, I used a clip that was about 10 minutes, however, testing clips 30+ minutes long and I would always get an error and the transcription would fail outright. You’ll have to experiment with the length of clips you upload to hugging face yourself to see what does and doesn’t work. If you have longer clips you could always split them into shorter clips for upload and transcription, then manually join the transcriptions as they’re received. This is obviously more time consuming.
Note
One thing to consider is regardless of the method you choose here you’ll likely have to do some manual cleanup of the output transcription. Even though this large v3 model is really good, like all models it is imperfect, and not exempt from hallucinations. It’s just the depth and type of hallucinations you’ll see are less extreme. For example a common hallucination I see is repeated text. Someone says “Hello” once in the audio but in the transcript it’s repeated several times. These aren’t that bad and pretty obvious to point out when reviewing transcripts. Smaller models such as
base,smallormediumwill often hallucinate entire parts of conversations that did not in fact happen. This may also depend one what language you’re transcribing.
Practice Ideas
Now that we have the transcript alongside our recorded audio we can practice. There’s a lot of subjectivity here on how to go about this, but personally I’ve been using methods from YouTuber Language Lords and a book from Margarita Madrigal called “Madrigal’s Magic Key to Spanish: A Creative and Proven Approach”.
Language Lords’ approach is in line with the immersion and comprehensive input discussion I mentioned in the intro. The basis is taking the input (in this case audio), and unrelentingly drilling it daily. Usually he focuses on one piece of content to drill. With the help of the transcript, you can take note of any verbs you may not know so that you can practice the conjugations. I like using the iOS app Conjugato for this, but unfortunately it doesn’t have EVERY Spanish verb, so you may want to create a Google Sheet as described in his video in such cases. You can use apps like Duolingo, Drops, Memrise, Babel, etc. to build out your subjective vocabulary based on subjects that matter most to you. Additionally, doing drills like “mirroring” (also discussed in his videos) you can start to internalize the common cadences and accent of a native speaker.
Madrigal’s approach is a little more akin to traditional class work, but it’s structured very well and ramps at a nice pace. I took the structure of the some of the exercises and developed a Fabric prompt in order to have an AI model spit out some contextually aware, custom tailored exercises for me to complete based on the input material. This just enforces some of the speaking exercises I spoke about in the paragraph above. I plan on talking more about Fabric, and maybe I’ll share the prompt I used for this, however, I want to be respectful of the writer’s work, which is quoted in my prompt, so if I do it’ll have to be thoughtfully.
Conclusion
If you made it this far, I hope this was useful for you. If nothing else, I hope you saw some of the possibilities and power of Whisper and how you might be able to work it into some of your productive or creative workflows.
Fun Fact:
Spanish is part of the quadfecta of “romance” languages (Spanish, Portuguese, Italian, French), and thus you get a lot of bang for your buck in terms of understanding core grammatical structures, phonetics, and verb conjugations should you want to pick one up after the other. Two of these are also top 5 in terms of the most spoken languages in the world per Ethnologue: